

We have failed to store and organize much of the rapidly accumulating scientific information in rigorous, principled ways, so that finding what we want and understanding what is already known become exhausting, frustating, stressful and increasingly costly experiences. For information to be usable, it must be stored and organized in ways that allow us to access it, to analyze it, to annotate it and to relate it to other information. Only then can we begin to understand what it means. Only with the adquisition of meaning we adquire knowledge.
Nanopublications are a Linked Data format for scholarly data publishing that has received considerable uptake in the last few years. We briefly explain here an approach to use and link nanopublications as a unifying framework to represent knowledge in a semantic way.
A nanopublication is a single publishable and citable entity that combines an assertion, the provenance of the assertion, and the provenance of the nanopublication. This information can be about anything, for example a relation between a gene and a disease. Nanopublications are fully expressed in a formal and machine-interpretable way, making scientific communication more effective and user-friendly. Furthermore, because nanopublications can be attributed and cited, they provide incentives for researchers to make their data available in standard formats that drive data accessibility and interoperability.
We illustrate here the uniqueness of the nanopublication-based scheme by representing three instances of the class Nanopublication, two instances of the classes Provenance and PublicationInfo , and one instance of the classes Assertion, Subject, Predicate and Object.
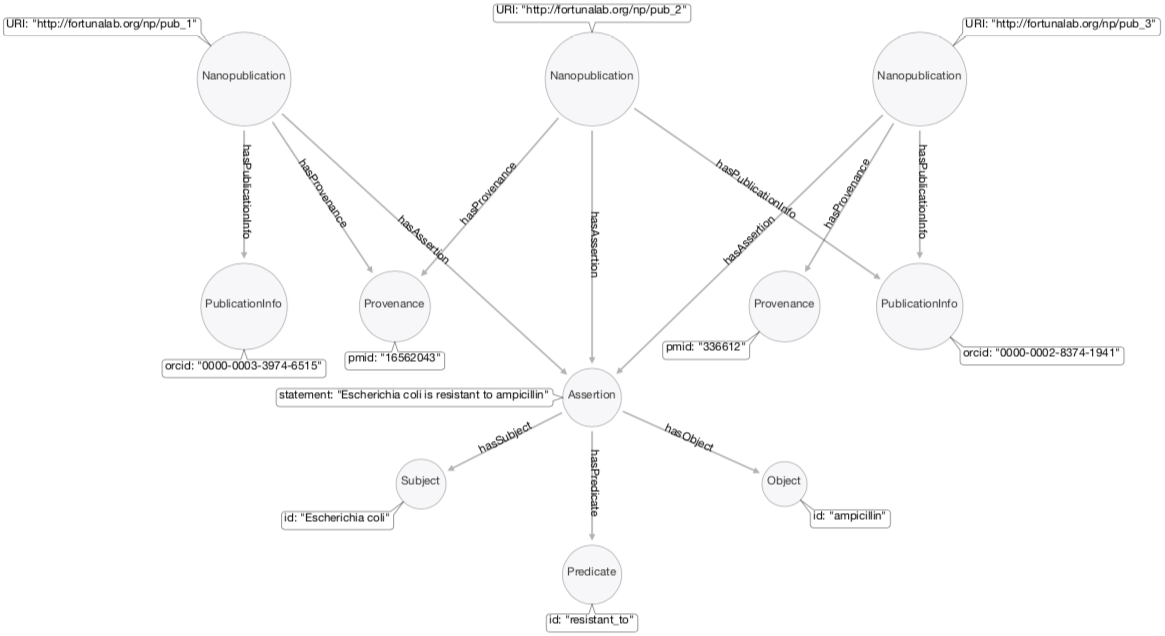
Nanopublications are identified by their URIs, that it, by pointing the address where the file is stored. Many nanopublications can share the same Assertion (e.g., the one identified by the following statement: "Escherichia coli is resistant to ampicillin"). However, they can only share a second class: either the Provenance of the assertion, e.g., the one identified by the PubMed ID 16562043 (i.e., a research paper published in 1965 in Journal of Bacteriology) or the PublicationInfo, e.g., the one identified by the ORCID 0000-0002-8374-1941 (i.e., the author of the nanopublication).
This means that more than one author (uniquely identified by his/her ORCID) can report the same assertion from the same provenance (e.g., a research paper), and the same author can report the same assertion from different provenances (e.g., distinct research papers). In fact, this is something good and desirable to happen.
Let's focus now on the instance of the Assertion class to understand how a collection of nanopublications, as the one shown in the above illustration, becomes a knowledge graph.
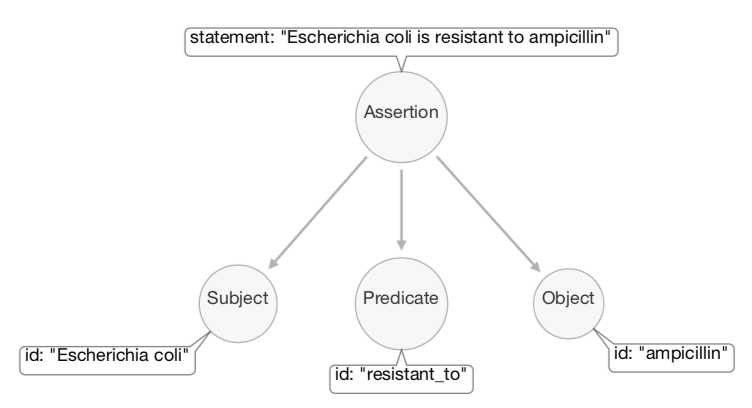
The instance of the class Assertion identified by the statement: "Escherichia coli is resistant to ampicillin" is a RDF graph (i.e., a triple consisting on a Subject, Predicate and Object).
The instance of the class Assertion takes its identifier (i.e., statement) by combining the three identifiers (id) of the instances of the classes it is linked to. If two instances of the class Assertion have the same identifiers for their Subject, Predicate and Object instances, the assertions will be linked by a synonymous relationship, regardless of the statement identifiers of the assertions (i.e., the same researcher might extract the same claim from the same publication but write it down in a slightly different natural language).
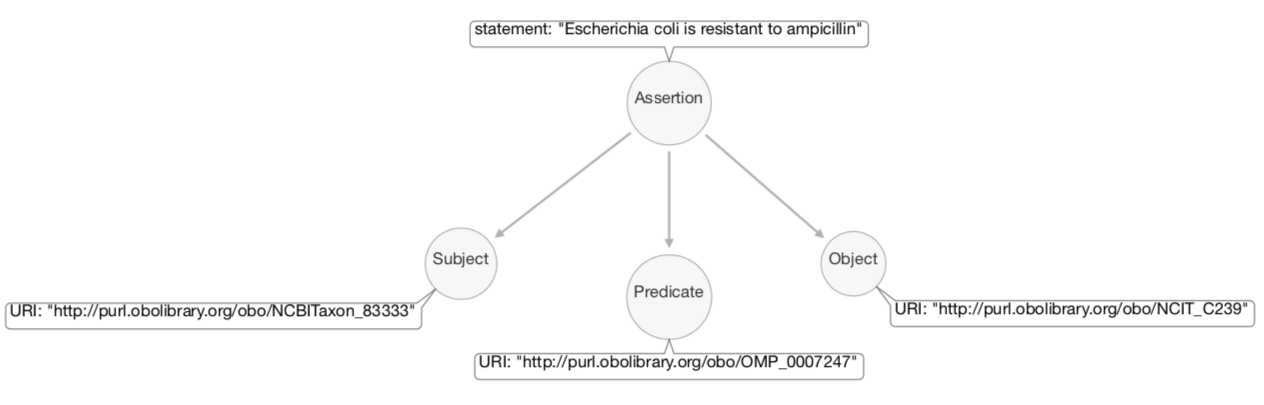
In RDF, the Subject of this triple is the URI of the taxon "Escherichia coli" (defined in the NCBI Taxon ontology ) the Predicate is the URI of the term "resistant to" (defined in the Ontology of Microbial Phenotypes), and the Object is the URI of the antibiotic "ampicillin" (defined in the NCI Thesaurus).
The instance of the class PublicationInfo identified by orcid: 0000-0003-3974-6515 is, in fact, another RDF graph (i.e., a triple consisting on a Subject, Predicate and Object).
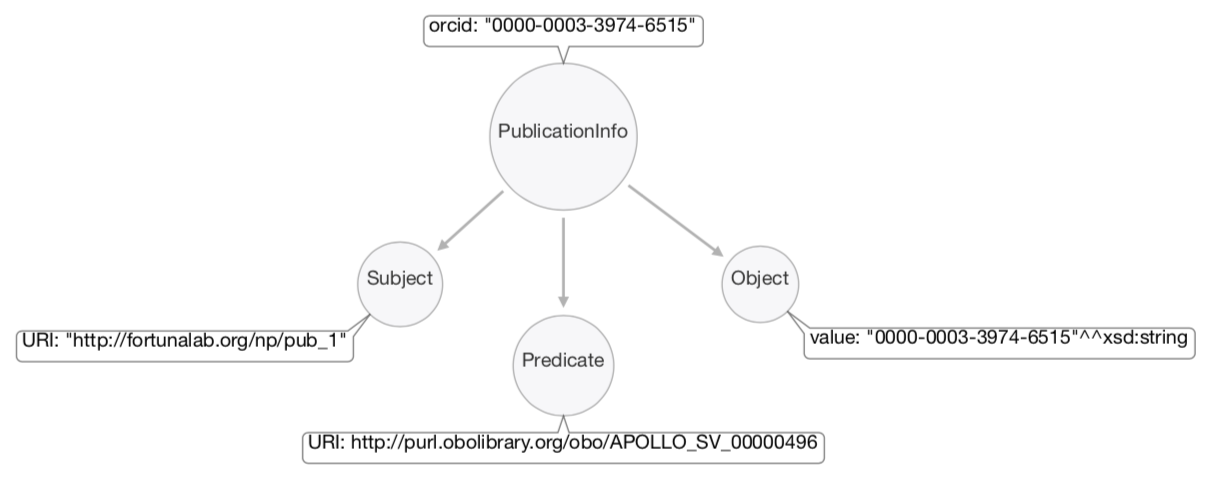
The Subject of this triple is the URI of the nanopublication, the Predicate is the ORCID, and the Object is the literal containg the value of the ORCID.
All resources in a triple (here, only the Subject and the Predicate) are represented in RDF by their URIs (they were meant to be read by machines). That's why the Predicate contains URI: http://purl.obolibrary.org/obo/APOLLO_SV_00000496 instead of ORCID. The Semantic Web encourages the use of URIs as names of things to use a common vocabulary, pointing at places where the meaning of the terms are clearly defined. The term ORCID, is defined in the Apollo Structured Vocabulary (Apollo-SV) ontology.
When the Object of a triple is not a resource (which means it cannot be the Subject of any triple), the datatype of the literal is indicated. We use here the XML Scheme Definition (http://www.w3.org/2001/XMLSchema) to indicate that the ORCID value is a string.
In natural language, this PublicationInfo triple reads: "This nanopublication was created by Carlos J. Melián".
Likewise, the instance of the class Provenance identified by pmid:336612 is, in fact, another RDF graph (i.e., a triple consisting on a Subject, Predicate and Object).
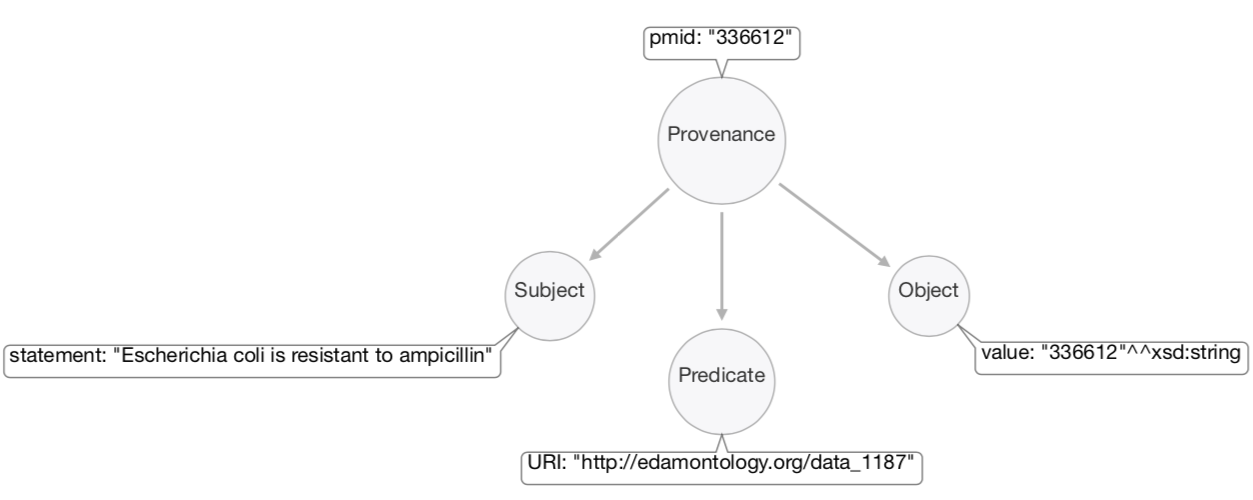
The Subject of this triple is the statement of the assertion, the Predicate is the URI of the PubMed ID term (i.e., pmid is defined in the EDAM Ontology), and the Object is the literal containg the value of the pmid (in this case, a research paper published in 1977 in Journal of Bacteriology).
In natural language, this Provenance triple reads: "The statement Escherichia coli is resistant to ampicillin was extracted from a publication having PubMed ID = 336612".
In summary, we should make published scientific literature more machine-readable, and hence more dynamic and informative. Nanopublications are a way of annotate semantically the scientific literature to understand the meaning of the published information and enable the linking to related documents.